
Spotify Track Popularity – Data pipelines, Analysis & Prediction
Created three pipelines for data transformations, Features most clearly distinguish a popular song, Most Popular Song and Artists
Created three pipelines for data transformations, Features most clearly distinguish a popular song, Most Popular Song and Artists

Disease Analysis in the United States - to gain meaningful insights from the disease data

This project is sponsored by Georgetown Analytics and Technology and goal is to predict the hiring status of the candidates

Model Interpretation, Predict the price for listings using listing descriptions and features that affected the price

Apache Spark as our big data analytics tool within the Hadoop ecosystem

Vector Autoregressive (VAR) model, Granger causality test:, ARIMA and SARIMAX used to determine the covid-19 forecasting in Boston

Built a portfolio using Modern Portfolio Theory (MPT) with one-year data [2020], calculated Value at Risk (VaR) and Conditional Value at Risk (CVaR) at a 99% confidence level for each trading day and week, forward tested the portfolio with the next year's data [2021], conducted hypothesis testing on the calculation described in step 3, and compared the results to the market benchmark - S&P 500, with returns presented in percentage and annualized.
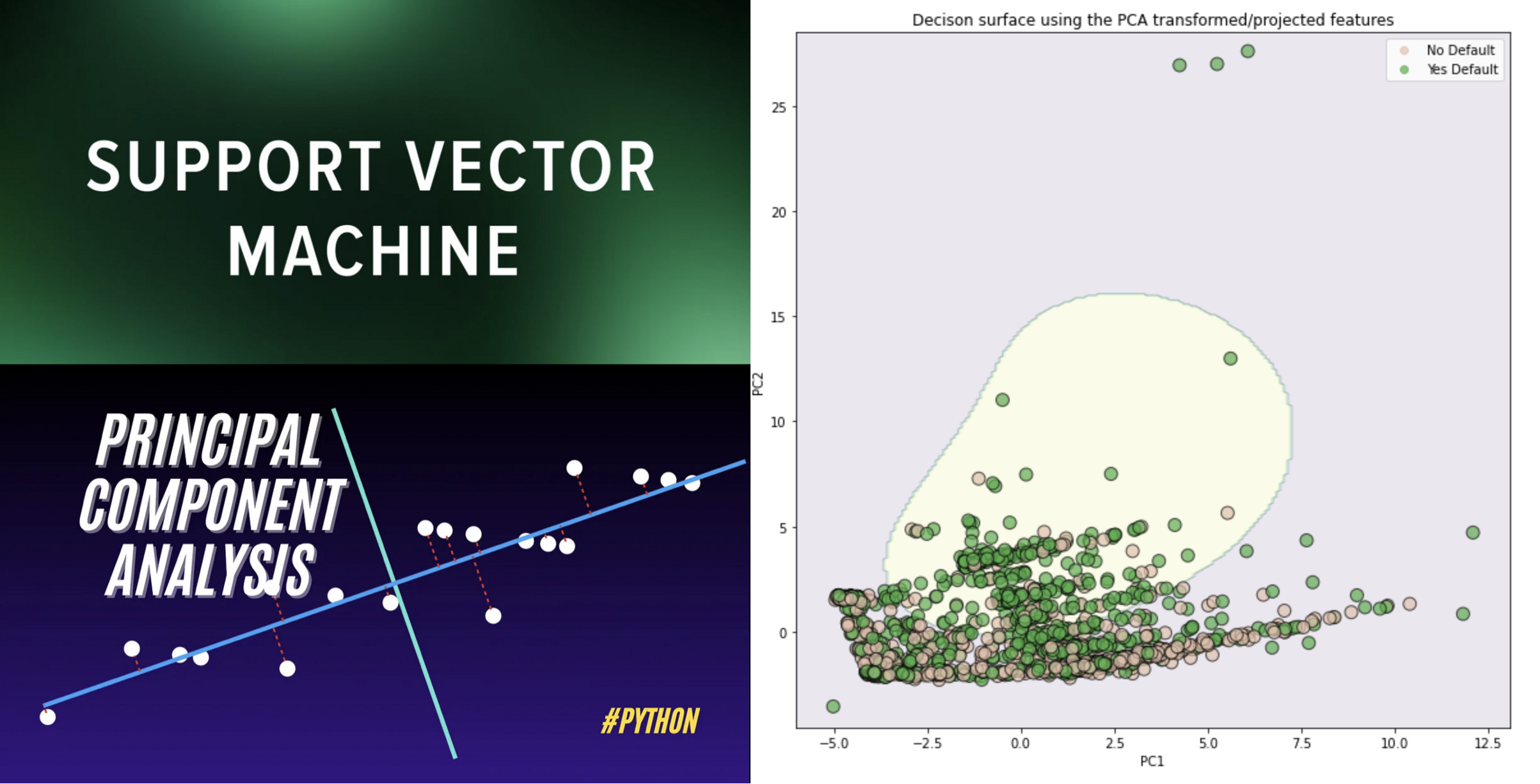
From the perspective of risk management, we are trying to classify - credible or not credible clients