🔗 Github repository
🔗 Dataset Source
Description
In this project, I have used the big data analytics tool, and performed an analysis on the metadata of the airline flights that occurred in the United States between the years 1987 and 2008. To begin, it is necessary for us to investigate the past of aviation in the United States.We chose Apache Spark as our big data analytics tool within the Hadoop ecosystem because spark is an open-source framework designed for ease of use, speed, and sophisticated analytics. In order to conduct our analysis, we relied on PySpark, which is essentially just the Python interface to Apache Spark. Research Questions: -
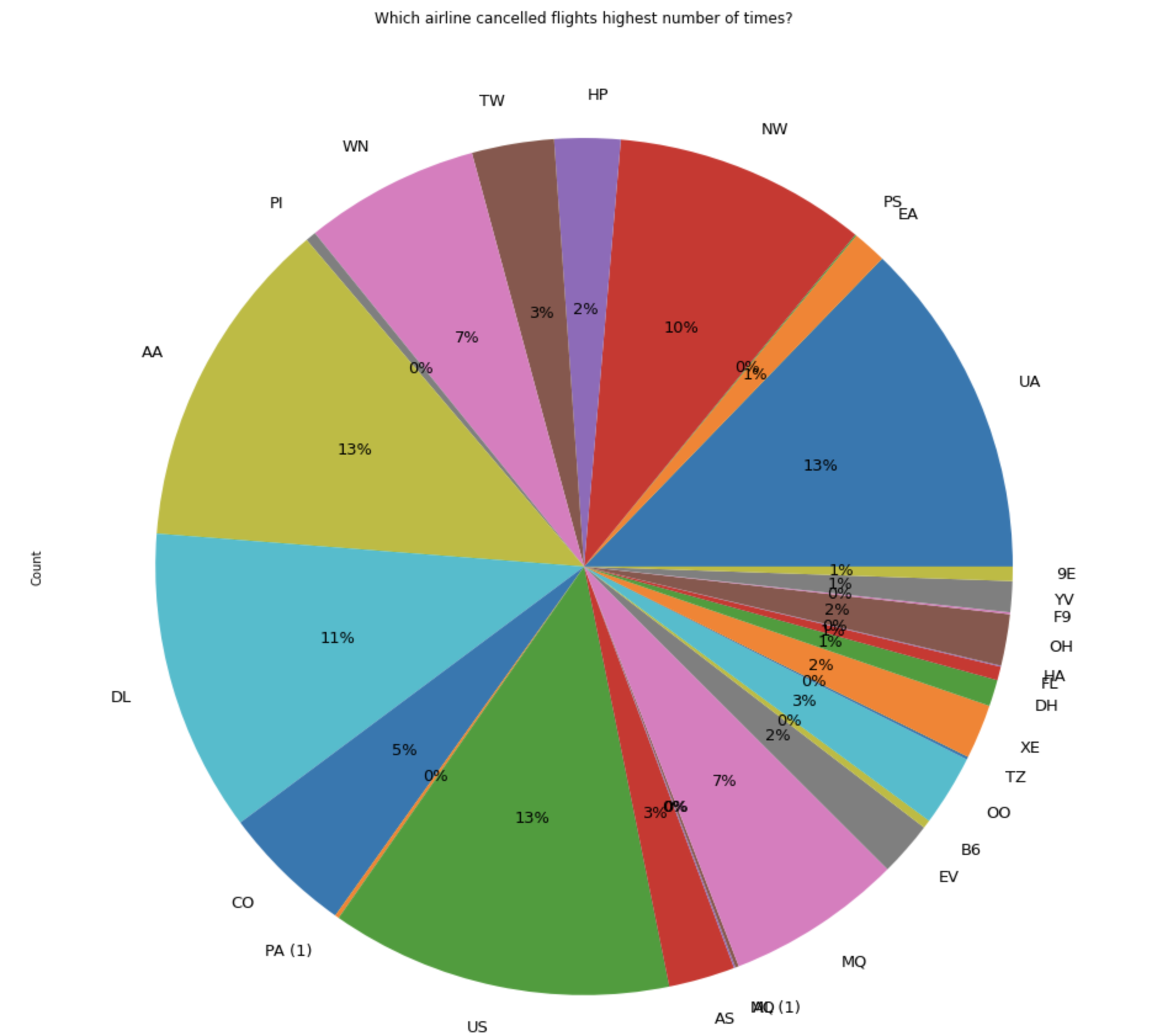
- Which airline has the greatest amount of cancelled flights? Why do these Airlines have the highest amount of cancellations, and what can those causes be?
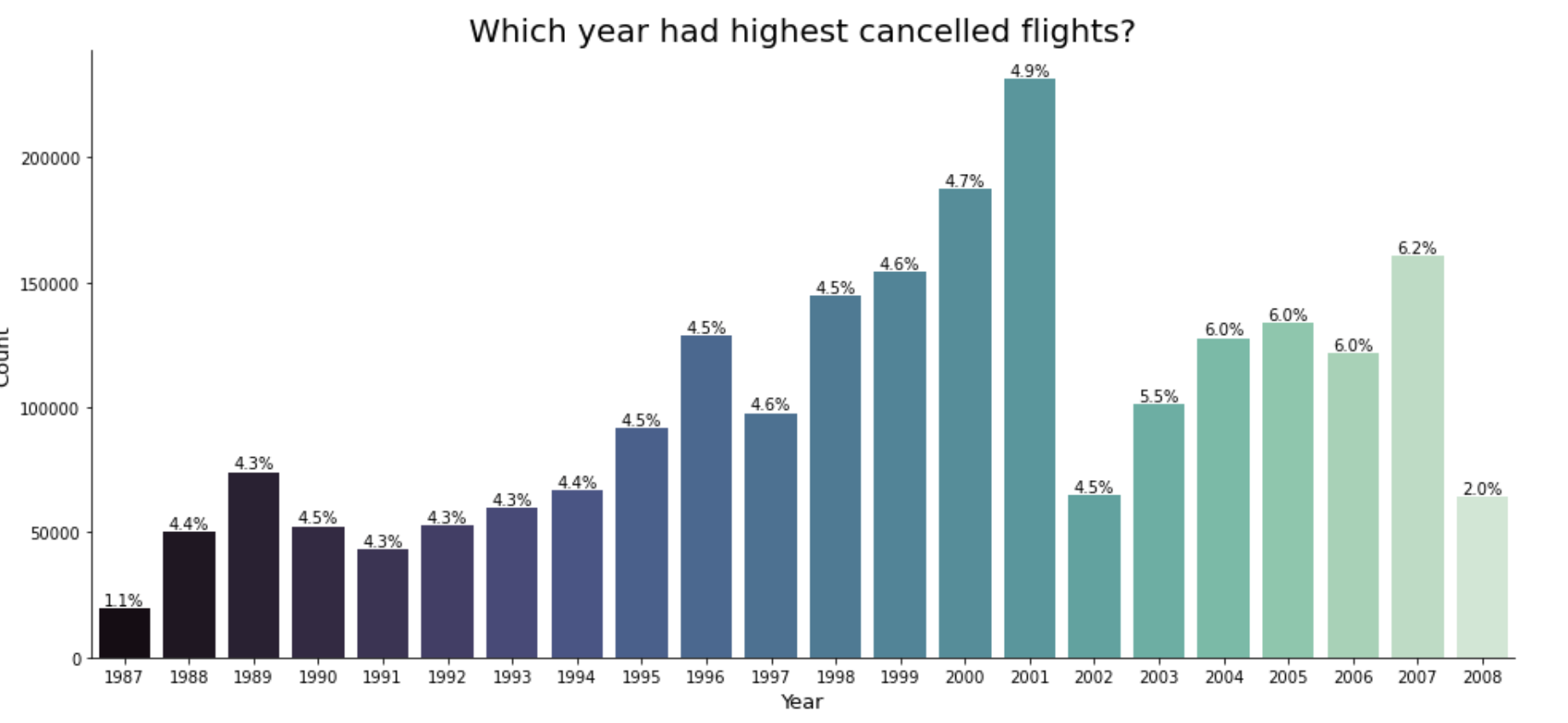
- Which year appears to have had the most flights cancelled overall, and what may the potential causes be? Is it wise to make decisions only based on data?
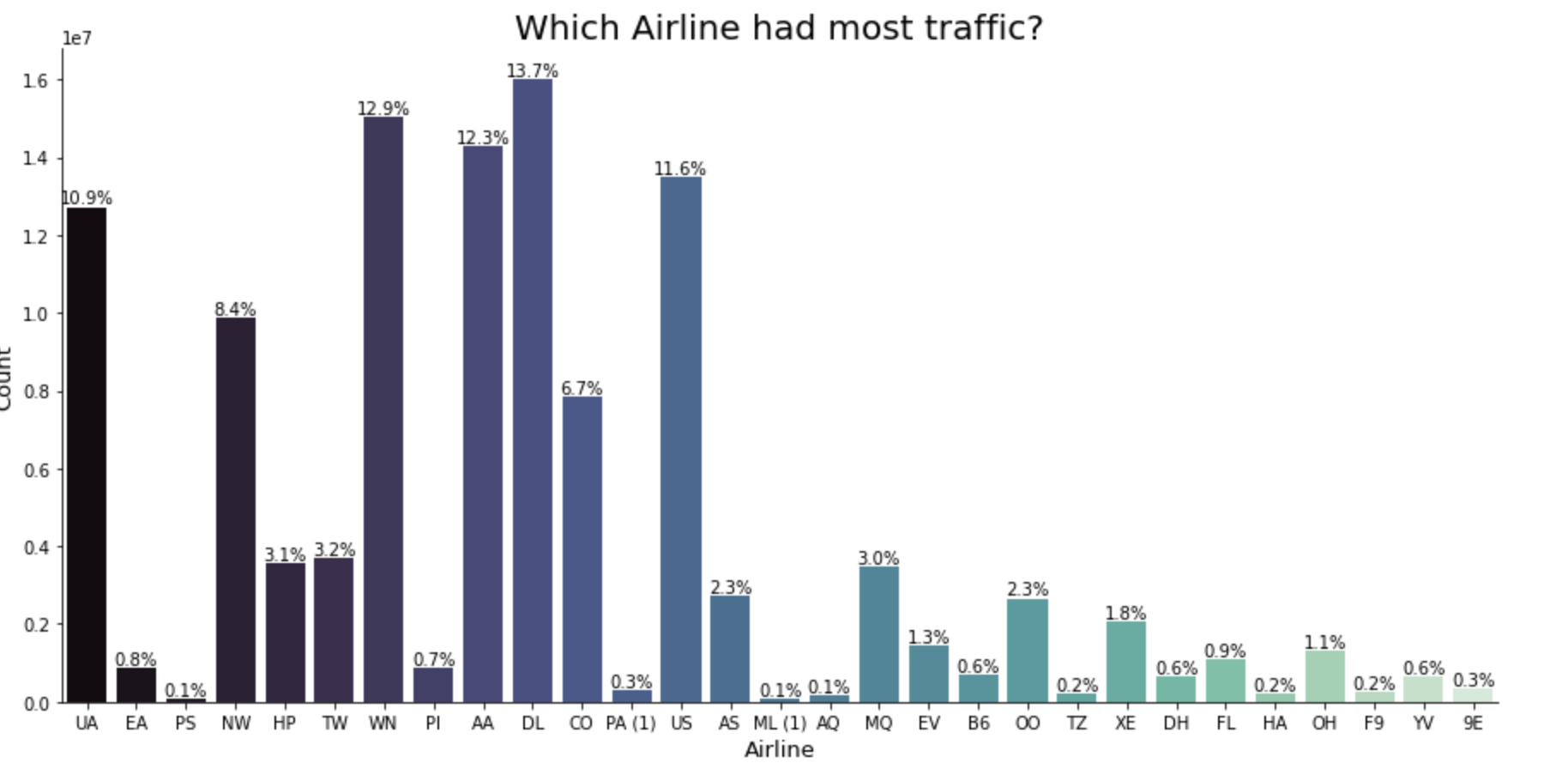
- Which domestic airline routes in the US had the largest flight traffic, and between which two stations?
- Which airline is the world’s biggest public airline companies by number of passengers carried between 1987 and 2008?
- Which airlines are the main rivals of the largest publicly traded airline corporations in the world in terms of passenger volume?
- Which year sees the most flight bookings and the aviation industry’s boom?
- Which month of the year do individuals most frequently travel?
- Which day of the month saw the highest number of passengers taking flights?
- Which day of the week saw the highest number of passengers taking flights
Methods and Key Findings
-
Method we need to start a spark session in order to make effective use of the spark framework and API in this project, we imported a function called SparkSession from the PySpark library and then started a spark session. And below you will find the code that we executed in order to create a sparksession.

-
Key Findings