
🔗 Github repository
🔗 Dataset Source
Intro
The objective of this project is to develop a machine learning model that accurately predicts the popularity of songs on the Spotify platform. Spotify is a popular music streaming service with a vast library of songs from various genres and artists. The popularity of a song is a crucial factor for both artists and users, as it determines the visibility, reach, and potential success of a song. I have conducted EDA and applied supervised and unsupervised ML methods to find the most popular songs and also we string together different user-defined Python functions to make a pipeline for processing data, I have created 3 small pipelines. I used over 600,000 Spotify tracks and 20 attributes in this project.
- What is the overall trend and impact of notable events on the music industry?
- Who are the most popular artists in the dataset?
- What are the most popular songs in the dataset?
- What types of machine learning models do well on this dataset?
- What characteristics most clearly characterize a popular song?
Key Findings
-
What is the overall trend and impact of notable events on the music industry?
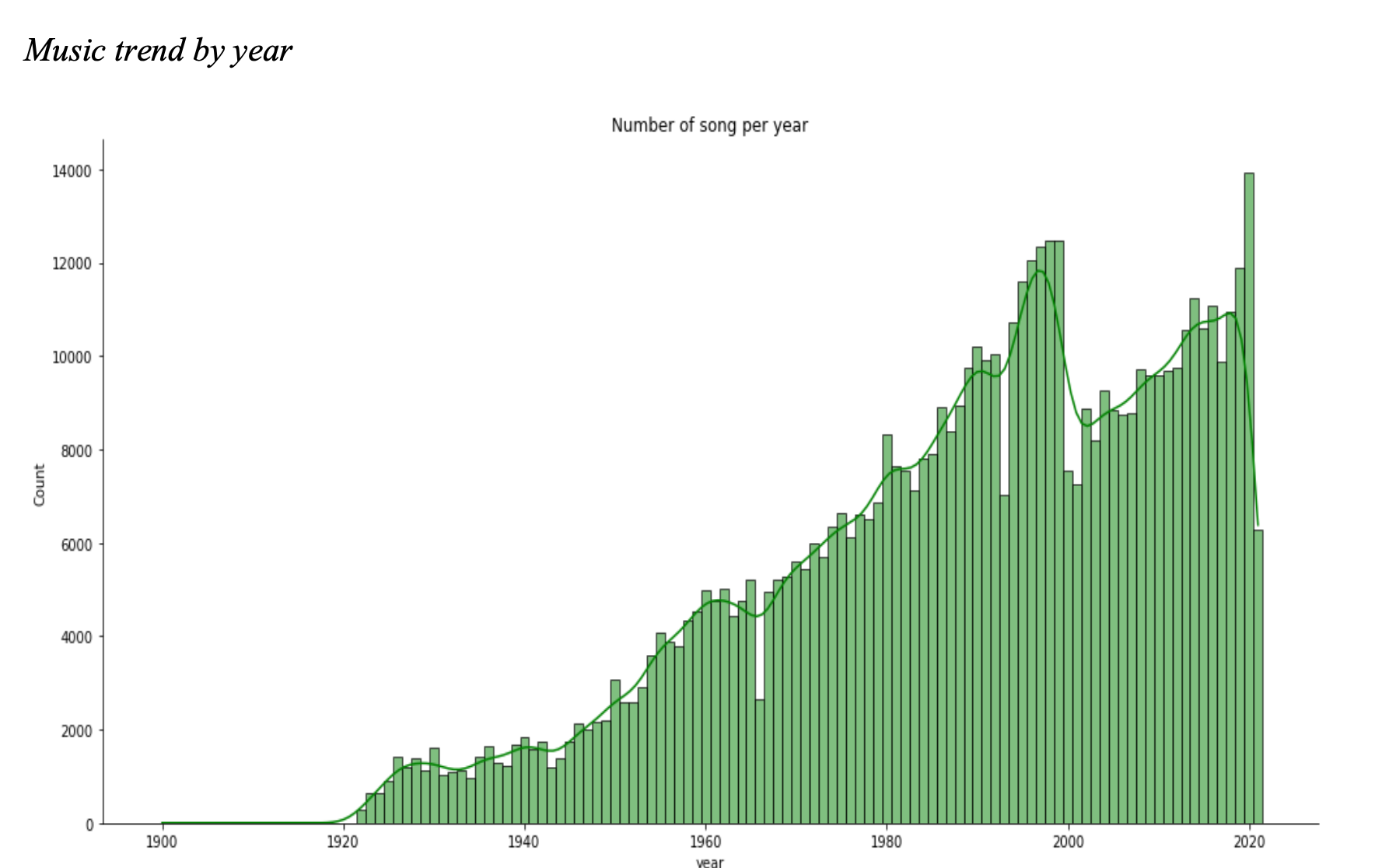 This graph illustrates the growing popularity of music over time, highlighting the current generation’s increased inclination towards music and the positive impact of digitization on the music industry. Notably, the graph indicates a significant decline in 2001, coinciding with the detrimental effects of the terrorist attacks. Furthermore, the music industry has thrived during the COVID-19 pandemic, with people seeking solace in music, resulting in its continued growth.
This graph illustrates the growing popularity of music over time, highlighting the current generation’s increased inclination towards music and the positive impact of digitization on the music industry. Notably, the graph indicates a significant decline in 2001, coinciding with the detrimental effects of the terrorist attacks. Furthermore, the music industry has thrived during the COVID-19 pandemic, with people seeking solace in music, resulting in its continued growth. -
Who are the most popular artists?
- A. Word Cloud for the most popular artists

- B. Bar Plot of the most popular artists
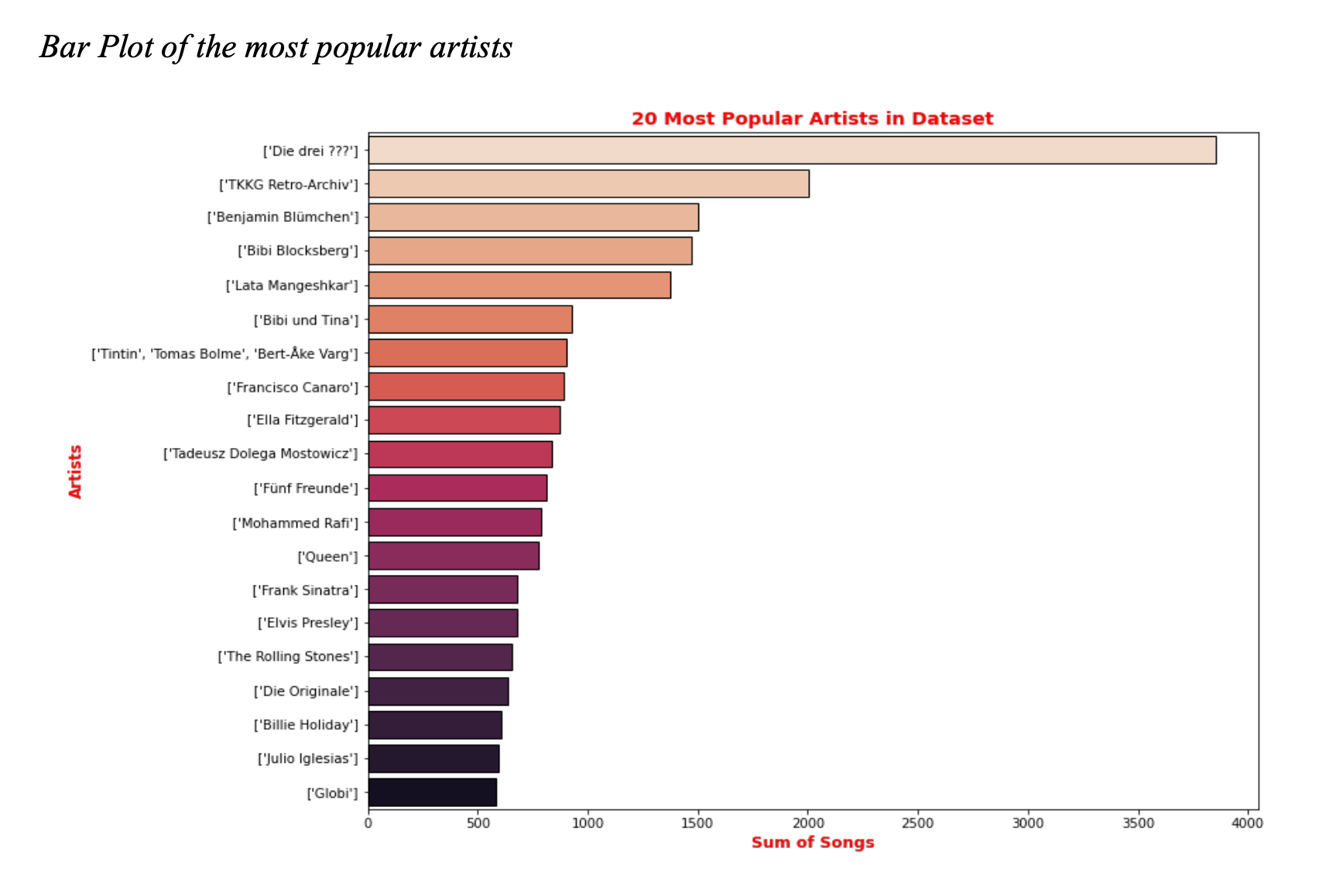
-
What are the most popular songs in the dataset?
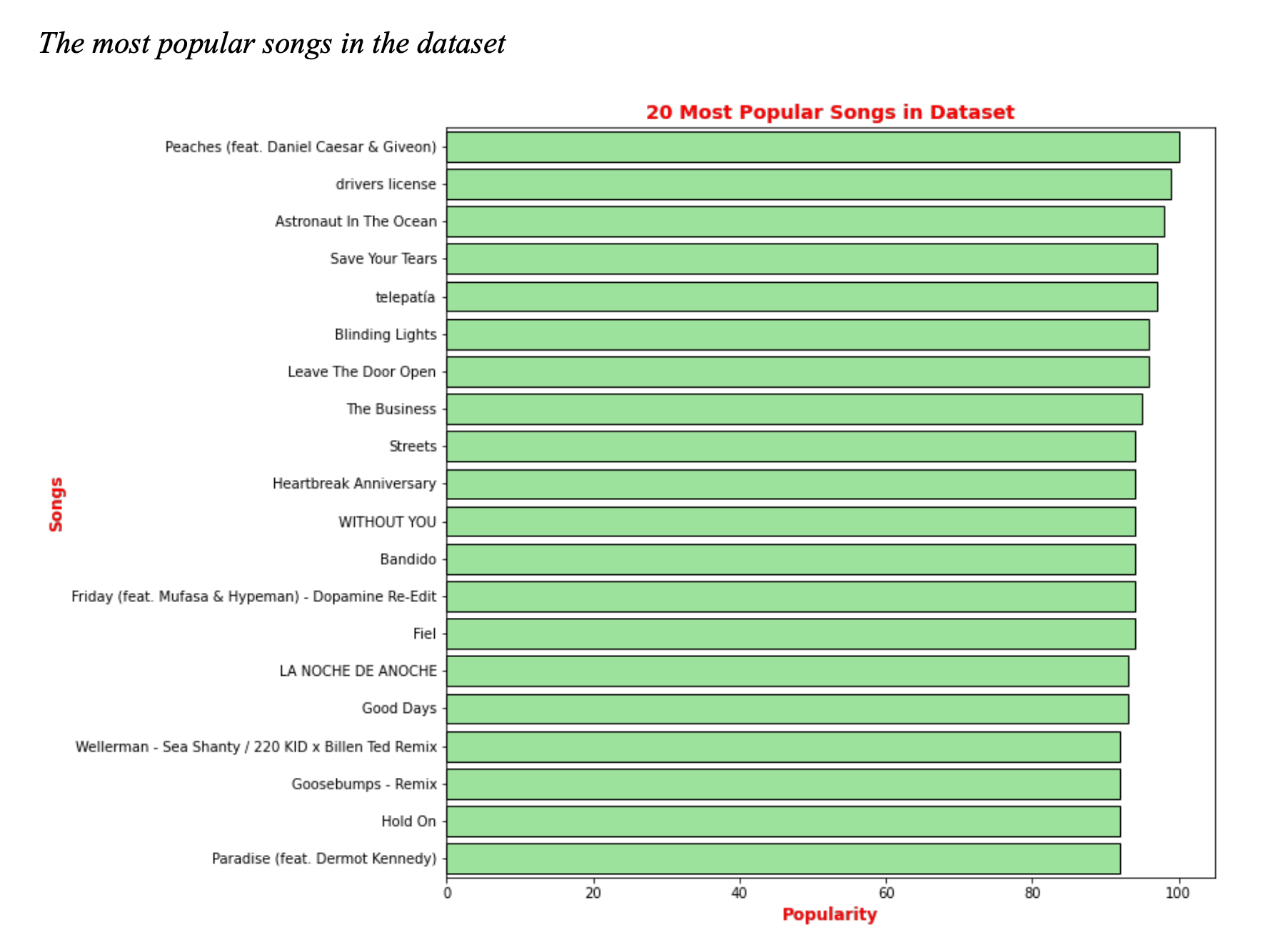
-
What characteristics most clearly characterize a popular song?
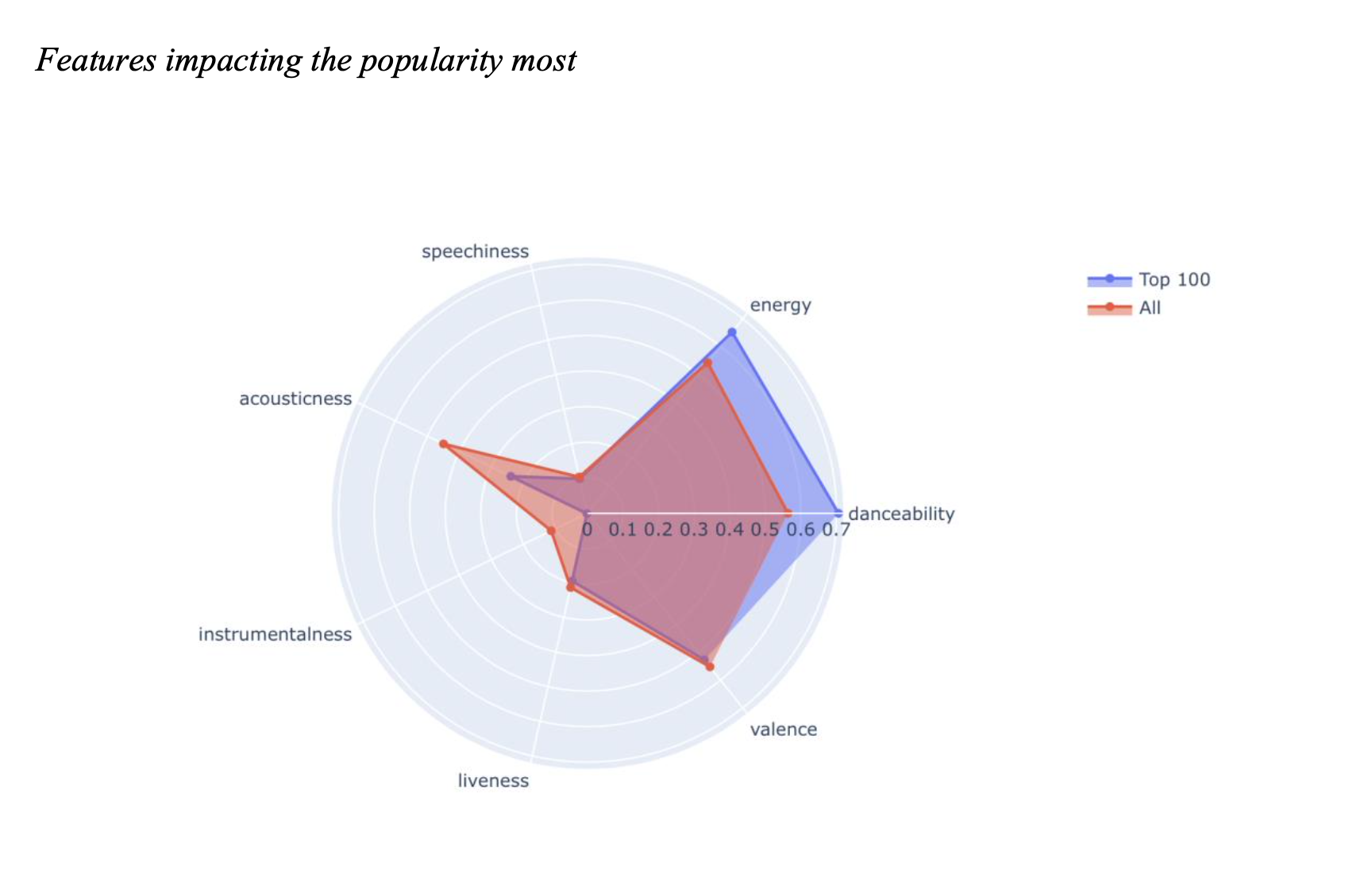 When we compared the most popular songs to all of the songs in the dataset, we discovered that songs with higher energy and danceability tend to become more popular. However, when
compared to standard songs, such popular songs lack acousticness and instrumentalness. Tracks released in recent years tend to be more popular.
When we compared the most popular songs to all of the songs in the dataset, we discovered that songs with higher energy and danceability tend to become more popular. However, when
compared to standard songs, such popular songs lack acousticness and instrumentalness. Tracks released in recent years tend to be more popular. -
Pipeline Building
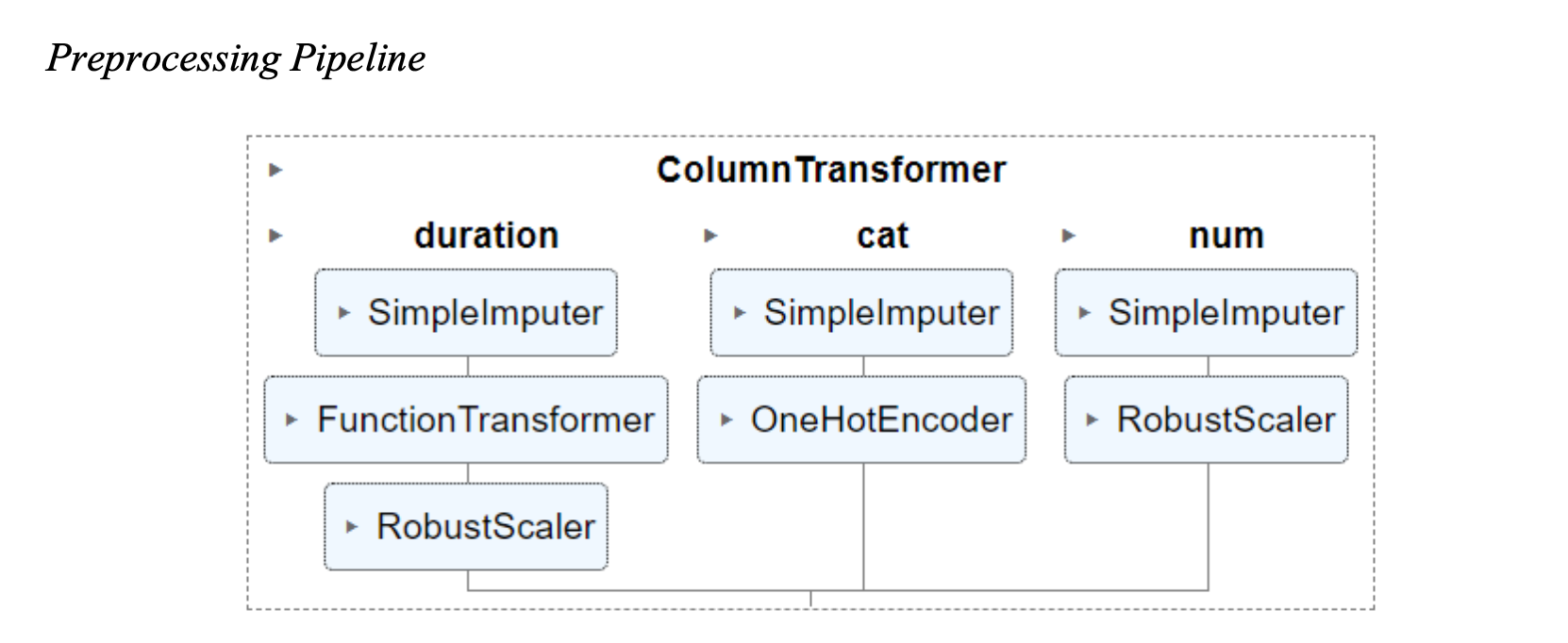 The pipelines in this process handle various transformations for different types of features. The first pipeline focuses on the ‘duration’ feature, replacing missing values with the median and converting the values from milliseconds to minutes. The feature is then scaled using RobustScaler to handle outliers effectively. The second pipeline aims to convert categorical variables into numerical ones using SimpleImputer and OneHotEncoder, but it is not applicable in the current dataset. Lastly, the third pipeline deals with numeric variables, replacing missing values with the median and scaling them using RobustScaler. All numeric characteristics are considered for this categorization problem.
The pipelines in this process handle various transformations for different types of features. The first pipeline focuses on the ‘duration’ feature, replacing missing values with the median and converting the values from milliseconds to minutes. The feature is then scaled using RobustScaler to handle outliers effectively. The second pipeline aims to convert categorical variables into numerical ones using SimpleImputer and OneHotEncoder, but it is not applicable in the current dataset. Lastly, the third pipeline deals with numeric variables, replacing missing values with the median and scaling them using RobustScaler. All numeric characteristics are considered for this categorization problem.
Conclusion and Future Work
We employed 3 models (Logistic Regression, Random Forest and XGBoost) and Random Forest performed best with an accuracy of almost 97%. We discovered that the most crucial features to consider are loudness, energy, valence, acousticness, and explicitness. These features have the greatest influence on popularity. After hyperparameter tuning, we didn’t see any appreciable improvements in the model’s performance, which may be attributed to the large dataset’s size, the lengthy training times associated with each combination, and the laptop’s technical limitations. Working with this dataset was really intriguing, and in the future, we’d like to conduct our study utilizing cloud computing on a more powerful system.