

🔗 Github repository
🔗 Dataset Source
Intro
This project is sponsored by Georgetown Analytics and Technology and its founder, Ernest Smiley. I had the opportunity to work with real-time data provided by Georgetown Analytics and Technology, gaining valuable insights into the field of talent management. The project “Unleashing AutoML for Talent Management ATS and HRIS Data” incorporates four datasets that are merged together for our analysis. The project aims to leverage AI technologies, specifically Automated Machine Learning (AutoML), in the field of talent management. The goal is to analyze ATS (Applicant Tracking System) and HRIS (Human Resources Information System) data to gain insights into hiring decisions and improve talent management outcomes.
Dataset
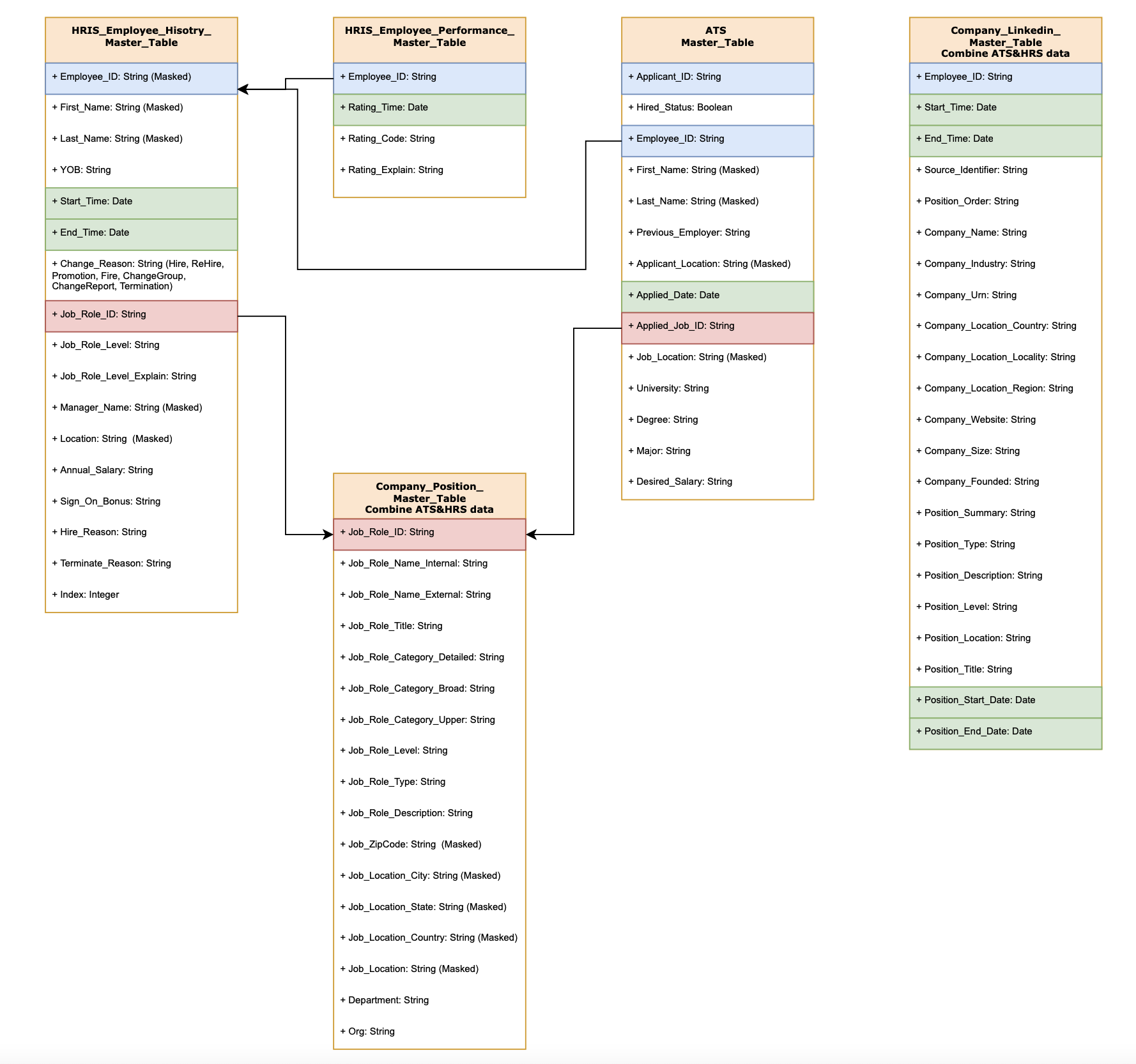 Data preprocessing step was performed on the dataset to drop unwanted variablles/features. The columns with missing values exceeding a threshold of 35%, namely “position_type”, " position description", “position_summary”, “company_founded”, company website",“company_location_locality”, “company_location_locality” and “company_url”, were identified and subsequently dropped from the dataset. So finally we are done with the data cleaning step now our next step is EDA which is to be performed all the 4 datasets.
Data preprocessing step was performed on the dataset to drop unwanted variablles/features. The columns with missing values exceeding a threshold of 35%, namely “position_type”, " position description", “position_summary”, “company_founded”, company website",“company_location_locality”, “company_location_locality” and “company_url”, were identified and subsequently dropped from the dataset. So finally we are done with the data cleaning step now our next step is EDA which is to be performed all the 4 datasets.
Problem Statement
The project addresses two specific problem statements: Hired_Status Prediction (Classification) and Salary Prediction (Regression). The classification model predicts the “Hired_Status” based on available features, while the regression model predicts salaries based on individual characteristics and experience.
Exploratory Data Analysis (EDA)
EDA was performed to gain insights into the data. Various questions were explored, including the distribution of job openings, the most cited reasons for job changes, salary distributions based on years of experience, popular job profiles, and job demand across different cities and countries.
Questions for Analysis: -
-
Which state exhibits both a high volume of job openings and a strong success rate in terms of successfully hired candidates?
-
What is the most cited reason for job changes among employees?
-
What is the overall distribution of salaries across the entire population?
-
Which countries have the highest job demand?
-
Which cities are the most popular for job seekers?
-
What are the top 10 industries with the highest number of companies?
Key Findings
-
Which state exhibits both a high volume of job openings and a strong success rate in terms of successfully hired candidates?
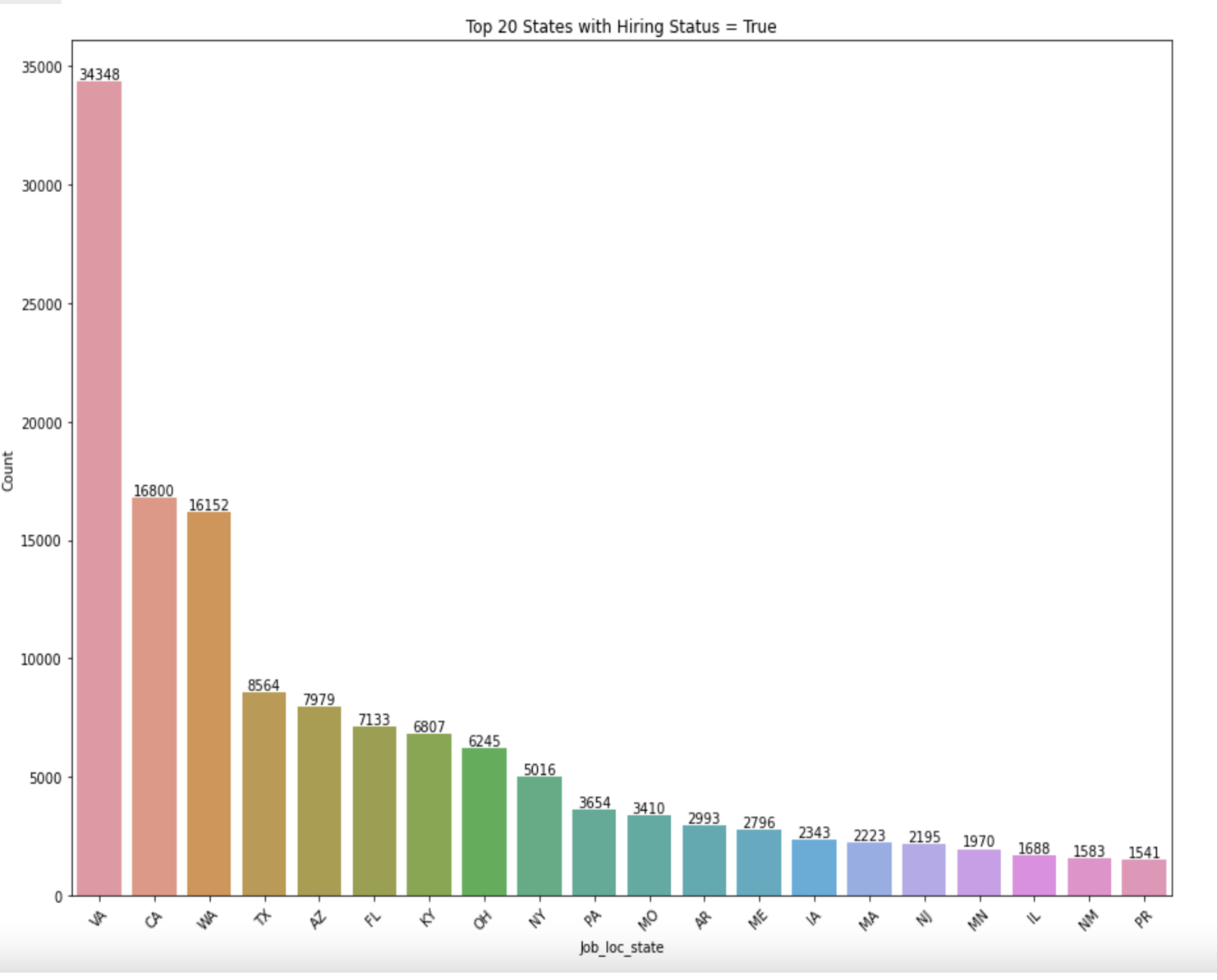 The graph indicates that Virginia City has the highest number of job openings and active hiring, followed by California in second place. Texas, Arizona, Florida, and New York are also among the top cities with a significant number of job openings. This means that Virginia City has the most job opportunities available and is actively hiring individuals. California is the second-highest city in terms of job openings, and Texas, Arizona, Florida, and New York also have a substantial number of job opportunities.
The graph indicates that Virginia City has the highest number of job openings and active hiring, followed by California in second place. Texas, Arizona, Florida, and New York are also among the top cities with a significant number of job openings. This means that Virginia City has the most job opportunities available and is actively hiring individuals. California is the second-highest city in terms of job openings, and Texas, Arizona, Florida, and New York also have a substantial number of job opportunities. -
What is the most cited reason for job changes among employees?
- Word Cloud for the most cited reason for job changes among employees
 According to the word cloud, the most commonly cited reasons for changing jobs are personal reasons and job change. In addition to unsatisfactory performance, early retirement, and misconduct are also among the top reasons. The word cloud visually represents the frequency of different reasons cited for changing jobs. The most prominent reasons mentioned by individuals are personal reasons and job change. This suggests that people often switch jobs due to personal factors or to pursue new career opportunities. Apart from those, unsatisfactory performance, early retirement, and misconduct are also cited as significant reasons for changing jobs.
According to the word cloud, the most commonly cited reasons for changing jobs are personal reasons and job change. In addition to unsatisfactory performance, early retirement, and misconduct are also among the top reasons. The word cloud visually represents the frequency of different reasons cited for changing jobs. The most prominent reasons mentioned by individuals are personal reasons and job change. This suggests that people often switch jobs due to personal factors or to pursue new career opportunities. Apart from those, unsatisfactory performance, early retirement, and misconduct are also cited as significant reasons for changing jobs.
-
What is the overall distribution of salaries across the entire population?
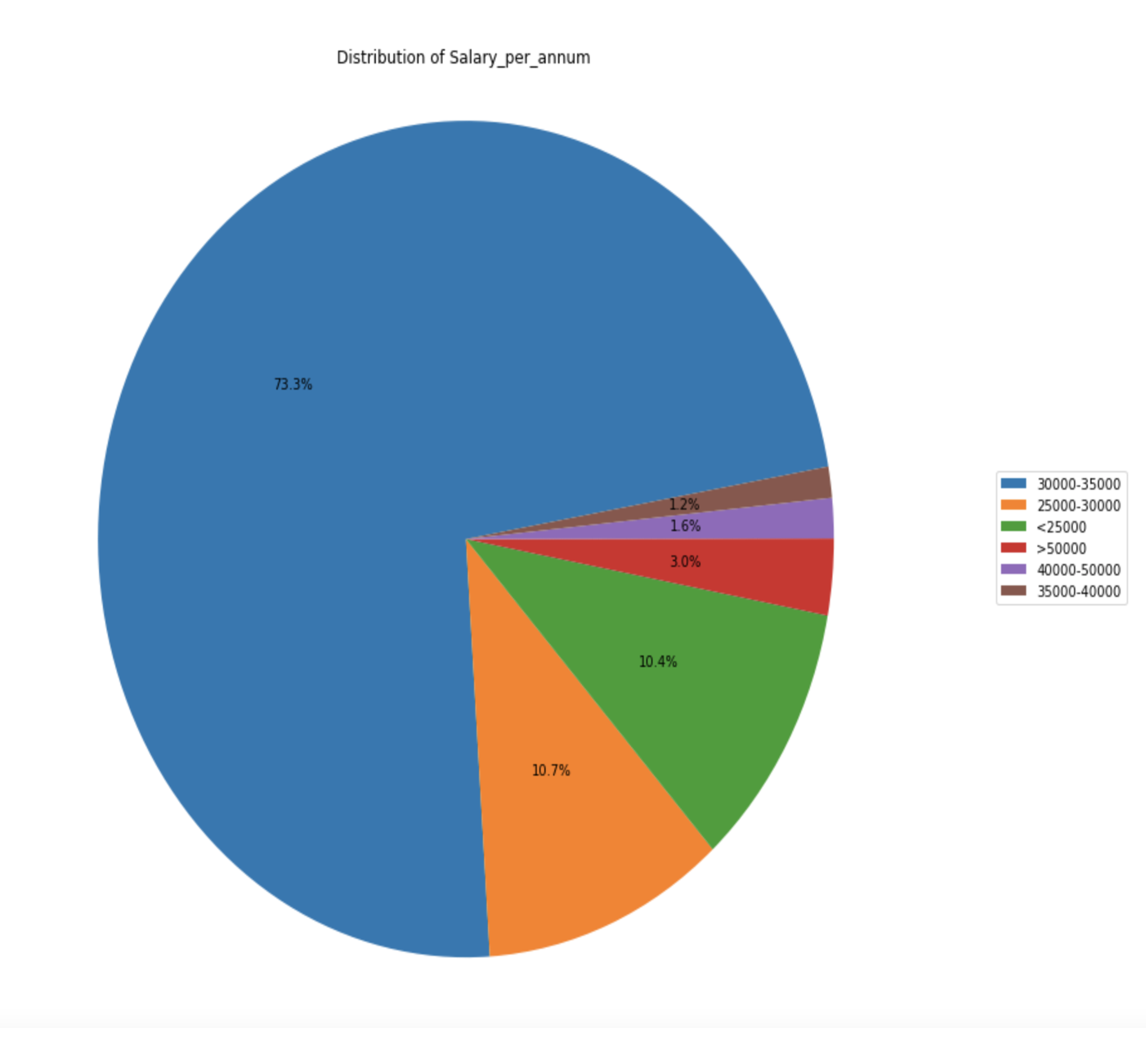 Approximately 73% of people have salaries ranging from $30,000 to $35,000, and this salary band has the highest number of individuals regardless of their years of experience and birth year. It seems that most people earn between $30,000 and $35,000. The second-highest percentage is 10.7% with a salary band of $25,000 to $30,000, and 10.4% earn less than $25,000. Therefore, approximately 95% of the population falls into a salary band lower than $35,000. This indicates that the majority of individuals (around 73%) earn salaries between $30,000 and $35,000. This salary band has the highest number of people, regardless of their years of experience or birth year. The second-highest percentage (10.7%) falls into the salary range of $25,000 to $30,000, and 10.4% earn less than $25,000. In total, approximately 95% of the population falls into a salary band lower than $35,000.
Approximately 73% of people have salaries ranging from $30,000 to $35,000, and this salary band has the highest number of individuals regardless of their years of experience and birth year. It seems that most people earn between $30,000 and $35,000. The second-highest percentage is 10.7% with a salary band of $25,000 to $30,000, and 10.4% earn less than $25,000. Therefore, approximately 95% of the population falls into a salary band lower than $35,000. This indicates that the majority of individuals (around 73%) earn salaries between $30,000 and $35,000. This salary band has the highest number of people, regardless of their years of experience or birth year. The second-highest percentage (10.7%) falls into the salary range of $25,000 to $30,000, and 10.4% earn less than $25,000. In total, approximately 95% of the population falls into a salary band lower than $35,000. -
Which countries have the highest job demand?
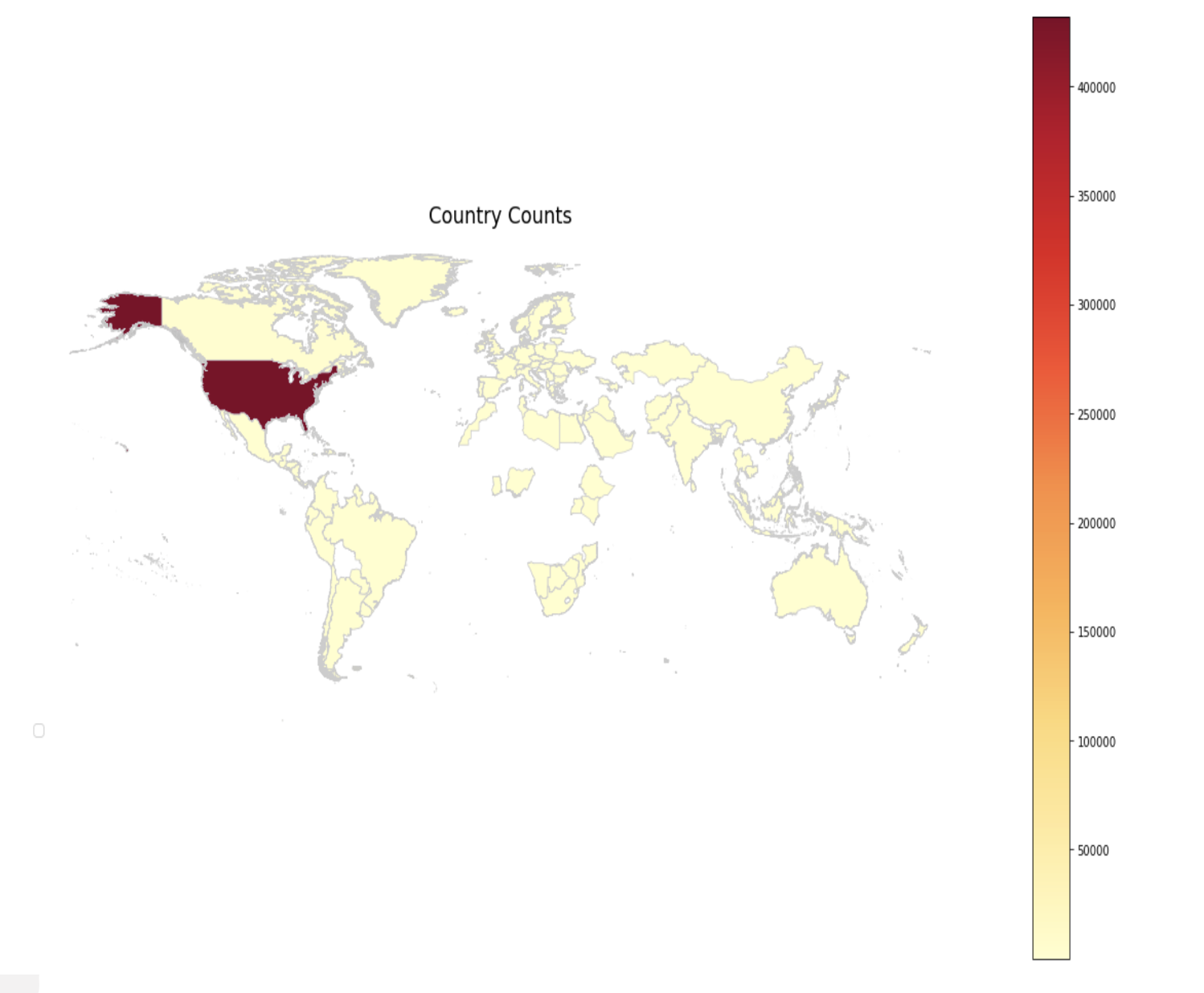 Among the countries, the USA stands out as having a higher frequency of hiring compared to other countries. This implies that the USA has a larger number of job openings and a more active job market compared to other countries represented in the data.
Among the countries, the USA stands out as having a higher frequency of hiring compared to other countries. This implies that the USA has a larger number of job openings and a more active job market compared to other countries represented in the data. -
Which cities are the most popular for job seekers?
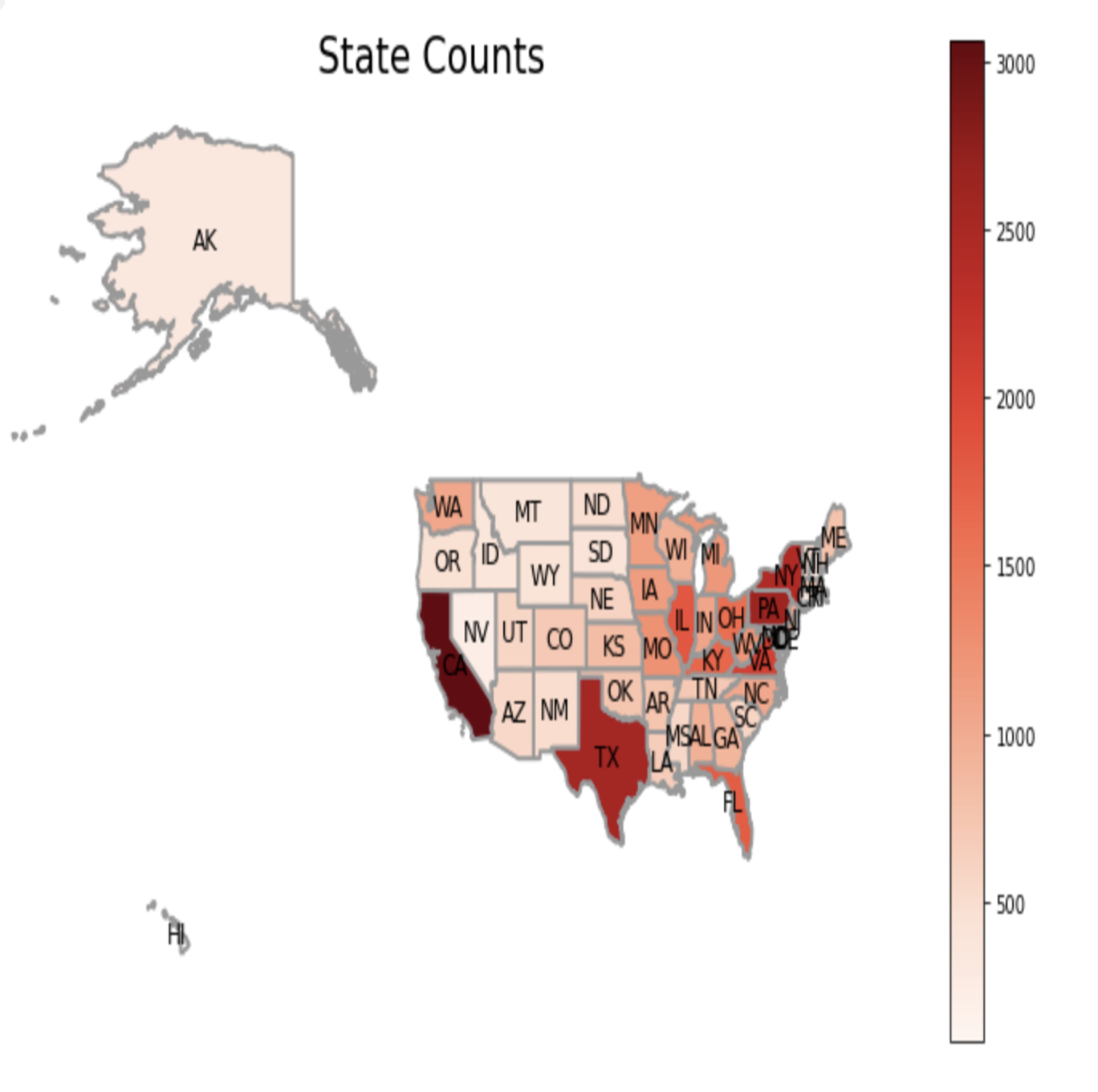 The geographical data graph represents the distribution of job openings across different cities. Based on the graph, it is evident that Texas and California are the top choices in terms of the highest number of job openings. These two states have a significant concentration of job opportunities compared to other cities or states.
The geographical data graph represents the distribution of job openings across different cities. Based on the graph, it is evident that Texas and California are the top choices in terms of the highest number of job openings. These two states have a significant concentration of job opportunities compared to other cities or states. -
What are the top 10 industries with the highest number of companies?
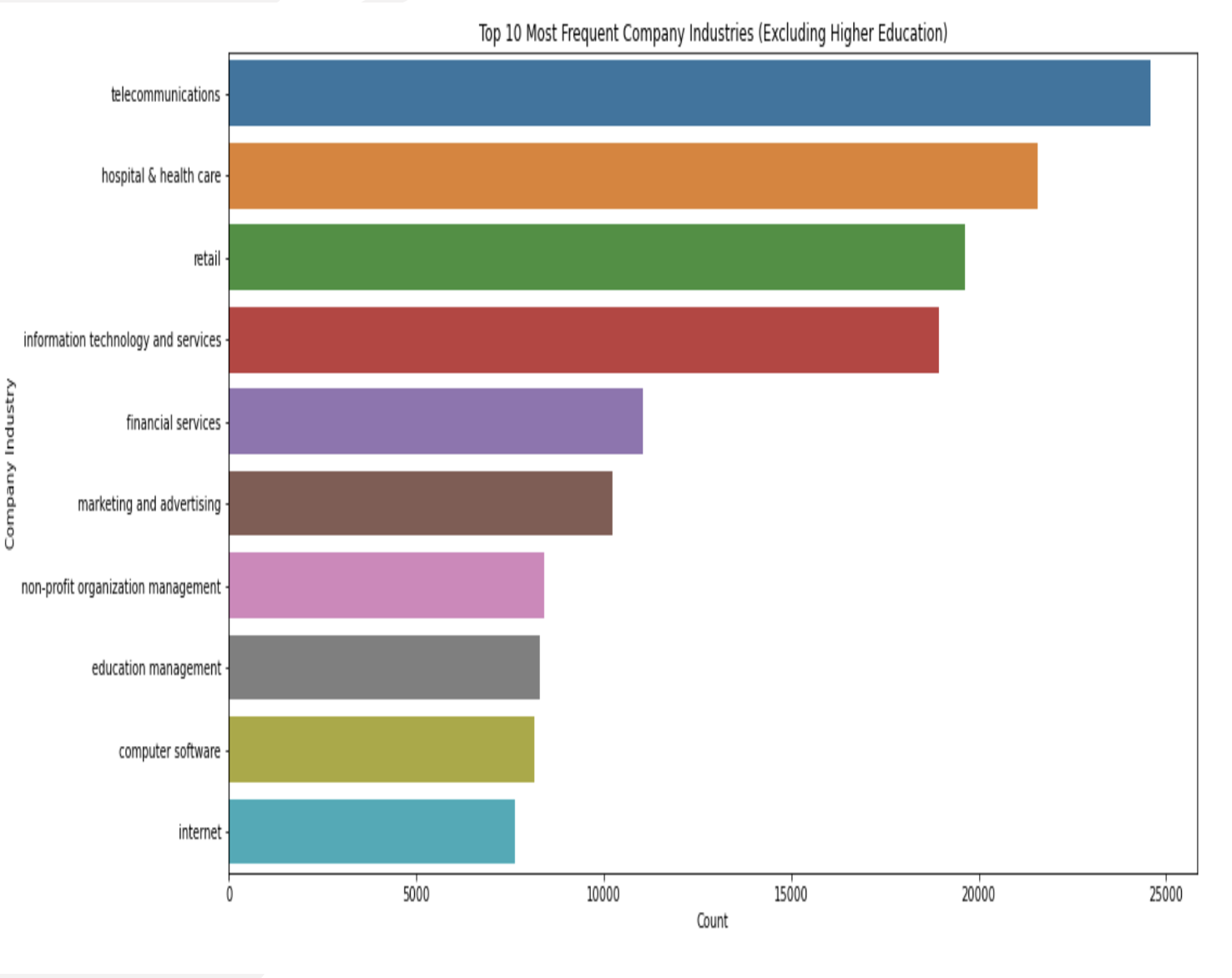 The bar chart provides information about the number of jobs in different sectors. From the chart, it is clear that the telecommunications and healthcare sectors have the highest number of jobs. These sectors are represented by the tallest bars in the chart, indicating a high frequency of job openings in those industries. This suggests that there are ample opportunities for employment within the telecommunications and healthcare sectors.
The bar chart provides information about the number of jobs in different sectors. From the chart, it is clear that the telecommunications and healthcare sectors have the highest number of jobs. These sectors are represented by the tallest bars in the chart, indicating a high frequency of job openings in those industries. This suggests that there are ample opportunities for employment within the telecommunications and healthcare sectors.
Oversampling(SMOTE):-Handling Imbalance Dataset
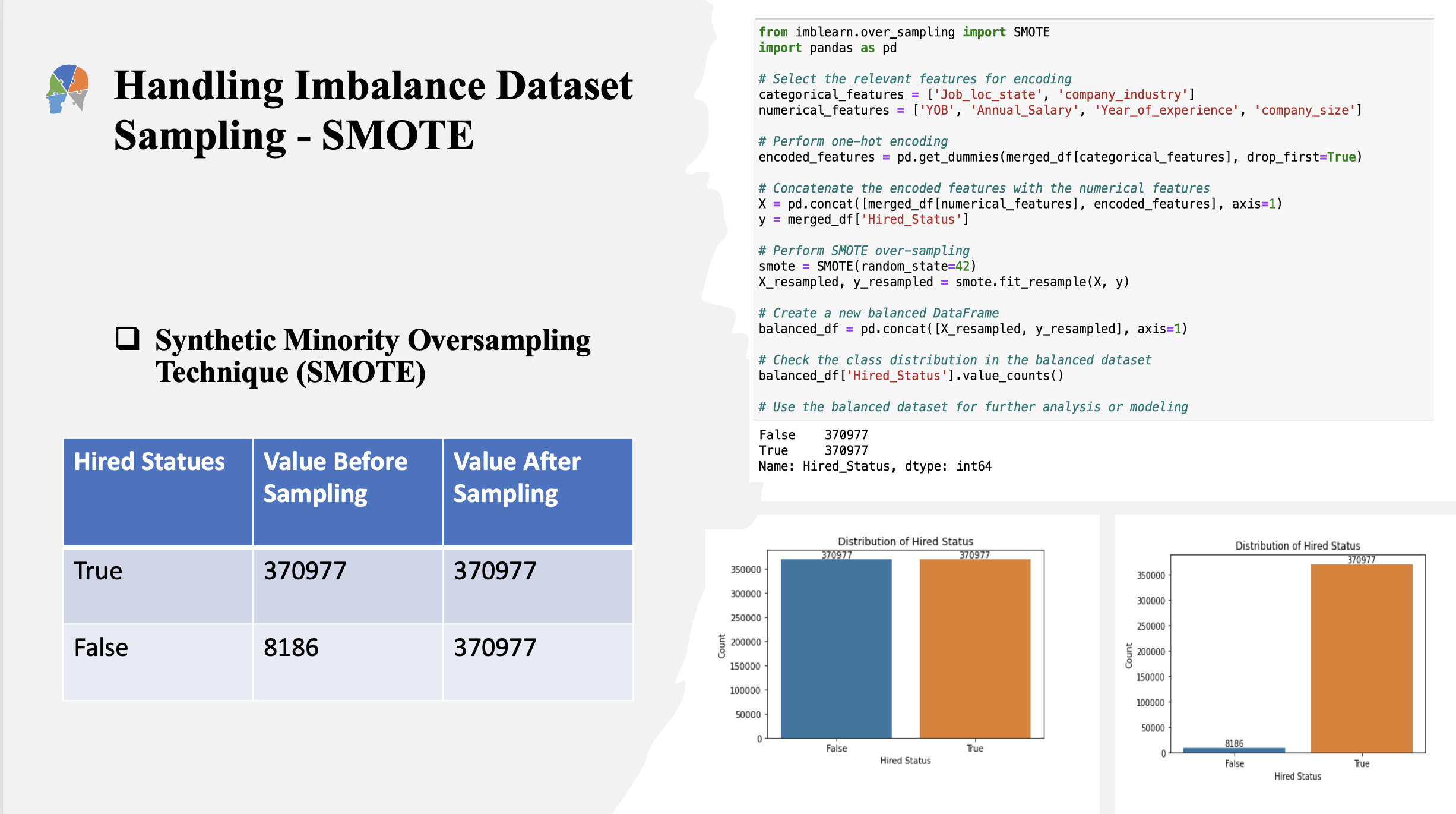 We have a dataset with two classes: “True” and “False.” Each class has a certain number of rows associated with it. The task at hand is to perform oversampling using the SMOTE (Synthetic Minority Over-sampling Technique) algorithm and observe how the number of rows changes before and after sampling.
Before oversampling, the dataset consists of 370,977 rows labeled as “True” and 8,186 rows labeled as “False.” This class imbalance indicates that the “False” class is underrepresented compared to the “True” class.
To address this class imbalance, we apply the SMOTE algorithm, which generates synthetic samples for the minority class (in this case, the “False” class) based on the existing samples. The algorithm creates new instances by interpolating between similar instances, effectively increasing the representation of the minority class.After performing oversampling with SMOTE, the number of rows in the “True” class remains the same at 370,977, as there is no need to create additional samples for the majority class.
However, the number of rows in the “False” class changes significantly. By applying SMOTE, the “False” class is augmented with synthetic samples, resulting in a new count of 370,977 rows. This equalizes the representation of both classes in the dataset, alleviating the class imbalance issue.
The oversampling process using SMOTE has effectively balanced the dataset, allowing for better modeling and prediction of both classes. This technique can help mitigate the negative impact of imbalanced data on machine learning algorithms, enabling them to learn from and generalize to minority class instances more effectively.
We have a dataset with two classes: “True” and “False.” Each class has a certain number of rows associated with it. The task at hand is to perform oversampling using the SMOTE (Synthetic Minority Over-sampling Technique) algorithm and observe how the number of rows changes before and after sampling.
Before oversampling, the dataset consists of 370,977 rows labeled as “True” and 8,186 rows labeled as “False.” This class imbalance indicates that the “False” class is underrepresented compared to the “True” class.
To address this class imbalance, we apply the SMOTE algorithm, which generates synthetic samples for the minority class (in this case, the “False” class) based on the existing samples. The algorithm creates new instances by interpolating between similar instances, effectively increasing the representation of the minority class.After performing oversampling with SMOTE, the number of rows in the “True” class remains the same at 370,977, as there is no need to create additional samples for the majority class.
However, the number of rows in the “False” class changes significantly. By applying SMOTE, the “False” class is augmented with synthetic samples, resulting in a new count of 370,977 rows. This equalizes the representation of both classes in the dataset, alleviating the class imbalance issue.
The oversampling process using SMOTE has effectively balanced the dataset, allowing for better modeling and prediction of both classes. This technique can help mitigate the negative impact of imbalanced data on machine learning algorithms, enabling them to learn from and generalize to minority class instances more effectively.
Conclusion and Future Work
In conclusion, the findings of this project highlight the importance of key numerical features, such as Annual Salary, Year of Birth (YOB), Year of Experience, and Job location, in predicting the hiring status of employees. The XG Boost model, specifically configured with a max_depth of 9, minimum child weight of 7, and learning_rate of 0.001, emerged as the most effective model for this prediction task. The integration of AI technology holds immense potential in enhancing the candidate selection process by automating repetitive tasks and efficiently identifying and ranking the best matches between resumes and job roles. Furthermore, the analysis reveals that the telecommunication and healthcare sectors exhibit the highest demand for jobs, while cities such as Texas, California, New York, and Pennsylvania are particularly popular among job seekers. Finally, the United States emerges as the leading country for job seekers, offering a multitude of employment opportunities. These insights provide valuable guidan ce for organizations and job seekers alike, facilitating informed decision-making in talent management and job search strategies. In future work, there are several avenues to explore based on the findings of this project. One potential direction is to utilize other talent management datasets using APIs, incorporating additional features such as skills, university information, and resume details. This expanded dataset can provide a more comprehensive understanding of candidate profiles and further improve the accuracy of predictions. Deep learning techniques, coupled with Natural Language Processing (NLP), can be applied to extract meaningful insights from these datasets, enabling a deeper understanding of candidate attributes and preferences.To gain a deeper understanding of the business implications and context surrounding talent management data, it would be valuable to delve into the intricacies of Applicant Tracking Systems (ATS), Human Resource Information Systems (HRIS), and other talent management systems. Conducting a survey or interviews with professionals in the field of people analytics and HR analytics can provide valuable insights into the challenges, best practices, and emerging trends in talent management. This knowledge can further inform the development of more robust and contextually relevant predictive models.